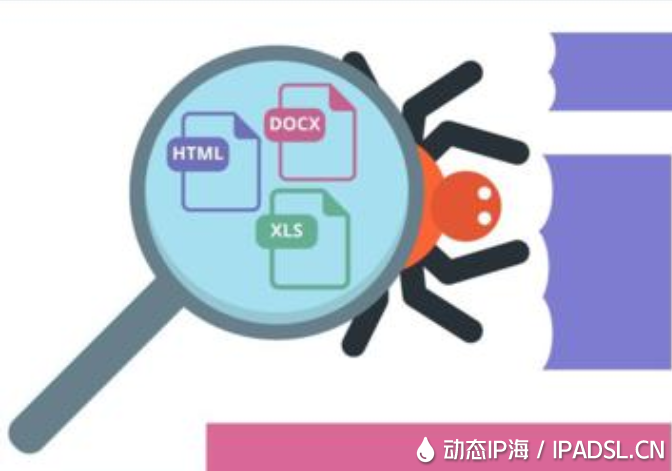
很多人看準了大數據是未來的趨勢,而現在的網絡電商已經是成果了,他們的業務核心需求來源于比價,會成立專門的爬蟲部門, 隨著爬蟲抓取數據的提速,及數據量抓取的龐大,問題也會凸
游戲不封號,那么大家都可以賺到錢了,但這對于做游戲的來說是不可能的事情。游戲里的封號不僅是技術問題,還要有充足的經驗,多試錯總結,還要有輔助工具的靈活運用,情況復雜,所以
很多人不明白為什么會有爬蟲這一技術?其實爬蟲最重要的不是學習技術,當你明白它的原理就會明白可以解決需要,方便生活。爬蟲的意義不是只在日常生活中,并解決了許多工作困擾的問題。
這些年以來,大數據的技術越發成熟,在國家發展經濟運行中變得越來越重要,對于我們生活也有了千萬般變化,為適應不同的應用需求,目前大數據相關項目基本覆蓋了存儲、計算、分析、集成
什么是爬蟲?簡單的說,就是把對網頁進行爬取然后把其中需要的數據提取出來,之后進行保存的一些列自動化操作; 爬蟲爬取的步驟很簡單,大多數是html代碼,也有的是js數據。網頁是基于htt
分布式系統指的是將一個硬件或是軟件組件分布在不同的網絡計算機上,彼此之間通過消息傳遞進行通信和協調的系統。而分布式事務是指事務的參與者、支持事務的服務器,資源管理器以及事務
在前面我們有講到ip代理都是在分布式爬蟲中得到了運用,為什么分布式爬蟲在企業中如此受到重視呢?不得不具體了解一下分布式爬蟲的原理了。
互聯網的爬蟲無處不在,一些過年回老家,出游的特價機票就會用到搶票軟件、購買返利等,背后是有許許多多的爬蟲在默默運作。那么ip代理在什么時候用到的呢?
剛入這個行業,除了基礎知識的了解,在實踐中爬蟲除了學習搜索引擎屬于無差別爬取外,也多多在垂直領域或特定網站內容的爬取。一名合格的爬蟲人員都要從網頁爬取、分析系統、鏈接發現
爬蟲一定遇到過這樣的問題,瀏覽過的網站必然留下了痕跡,特別是這種高頻繁的工作強度,有什么方法可以隱藏痕跡的方法呢?今天就來學習換IP可以保護個人資料后,還能繼續下一步的資料
<li id="ccmsa"></li>